Putting text on a plot is not that straight on, especially if there's more than one line of text.
data(iris)
# put the summary output into a variable
out <- capture.output(
summary(lm(Sepal.Length ~ Species + Petal.Width, iris)) )
cat( out, sep="\n" )
# create plot
plot.new()
# print text in mono font
text(labels=out, x=0
, y=rev(1:length(out)) * strheight( "S", cex=0.8 ) * 1.3
, adj=c(0,0), family="mono", cex=0.8 )

This is what I thought so far. Of course it is straight on to place bulk text on several lines, stupid...
Just collapse the text with newline as separator:
text(labels=paste(out, collapse="\n"), x=0, y=0
, adj=c(0,0), family="mono", cex=0.8 )




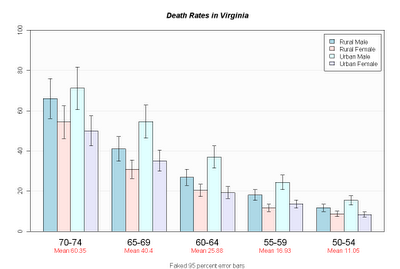
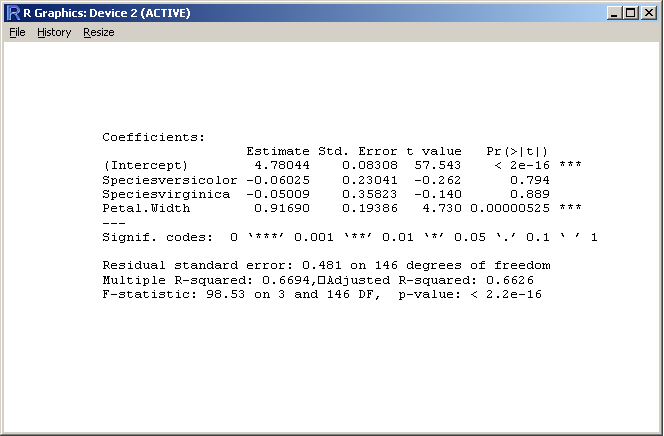
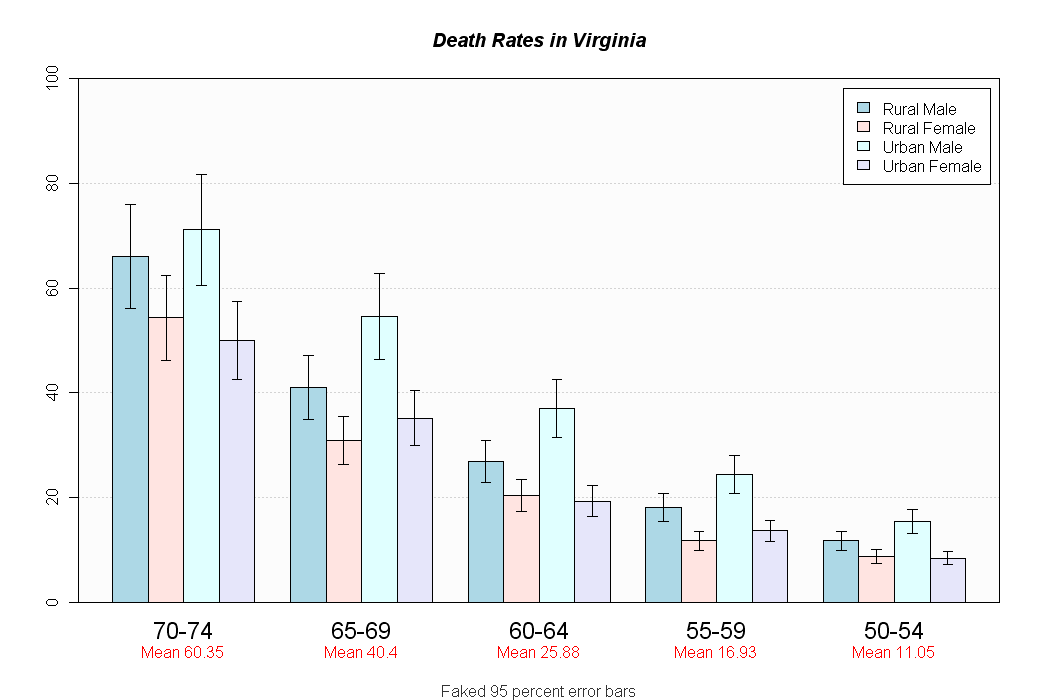{kind=link}